CPU缓存
CPU cache line
- 多核CPU中L1 L2 cache是独立的,L3是共享的
- L1 Cache 通常会分为「数据缓存」和「指令缓存」
- CPU 访问 L1 Cache 只需要 2
4 个时钟周期,访问 L2 Cache 大约 1020 个时钟周期,访问 L3 Cache 大约 2060 个时钟周期,而访问内存速度大概在 200300 个 时钟周期之间。 - cache line是数据读写的基本单元
- cache line由tag和data block组成
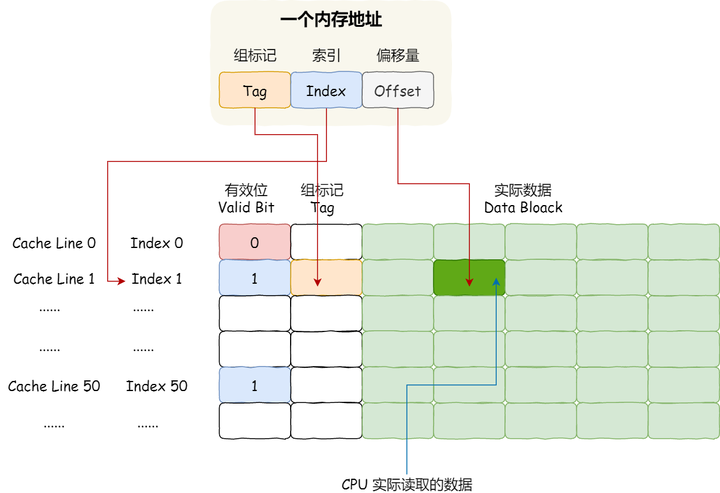
- 一个内存的访问地址,包括组标记、CPU Line 索引、偏移量这三种信息,于是 CPU 就能通过这些信息,在 CPU Cache 中找到缓存的数据。而对于 CPU Cache 里的数据结构,则是由索引 + 有效位 + 组标记 + 数据块组成。
数据写入
- cpu需要的数据从内存读入到cache line,发生修改时要写回到内存。这就是cache和内存的一致性。
- 有两个方式来保持一致性:
- 写直达:把数据同时写入内存和cache
- 回写:当发生写操作时,新的数据仅仅被写入 Cache Block 里,只有当修改过的 Cache Block「被替换」时才需要写到内存中,减少了数据写回内存的频率,这样便可以提高系统的性能。
cache line 数据一致性
多核CPU的L1 L2是独立的,因此出现了内存中一个数据会出现在多个L1中的情况,而且被多个CPU读写,因此需要保持一致性。
保证一致性需要以下两点:
- 某个 CPU 核心里的 Cache 数据更新时,必须要传播到其他核心的 Cache,这个称为写传播(Wreite Propagation);
- 某个 CPU 核心里对数据的操作顺序,必须在其他核心看起来顺序是一样的,这个称为事务的串形化(Transaction Serialization)。
要实现事务串形化,要做到 2 点:
- CPU 核心对于 Cache 中数据的操作,需要同步给其他 CPU 核心;
- 要引入「锁」的概念,如果两个 CPU 核心里有相同数据的 Cache,那么对于这个 Cache 数据的更新,只有拿到了「锁」,才能进行对应的数据更新。
Bus Snooping & MESI
- 这两个技术是保证一致性的技术方案。
Bus Snooping
- 当 A 号 CPU 核心修改了 L1 Cache 中 i 变量的值,通过总线把这个事件广播通知给其他所有的核心,然后每个 CPU 核心都会监听总线上的广播事件,并检查是否有相同的数据在自己的 L1 Cache 里面,如果 B 号 CPU 核心的 L1 Cache 中有该数据,那么也需要把该数据更新到自己的 L1 Cache。
NESI
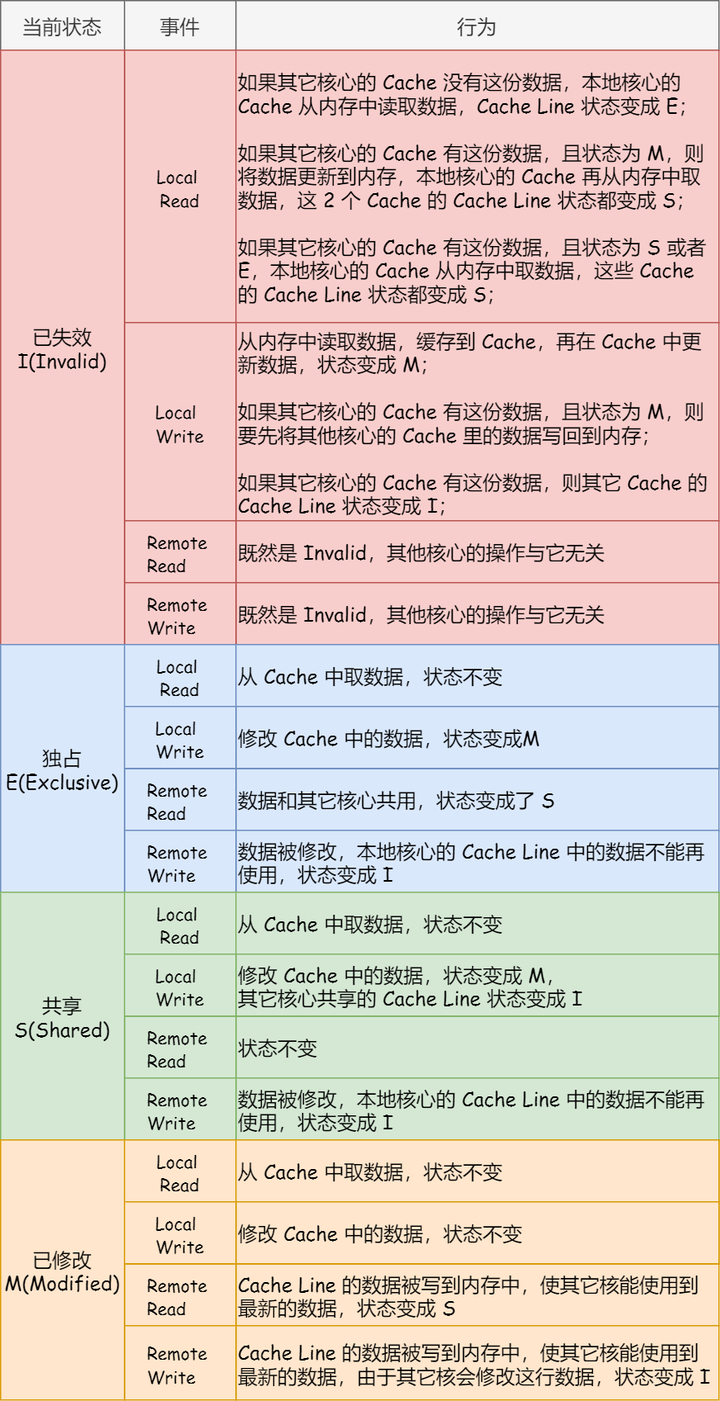
MESI 协议其实是 4 个状态单词的开头字母缩写,分别是:
- Modified,已修改
- Exclusive,独占
- Shared,共享
- Invalidated,已失效
这四个状态来标记 Cache Line 四个不同的状态:
- 「已修改」状态就是我们前面提到的脏标记,代表该 Cache Block 上的数据已经被更新过,但是还没有写到内存里。而「已失效」状态,表示的是这Cache Block 里的数据已经失效了,不可以读取该状态的数据。
- 「独占」和「共享」状态都代表 Cache Block 里的数据是干净的,也就是说,这个时候 Cache Block 里的数据和内存里面的数据是一致性的。
- 「独占」和「共享」的差别在于,独占状态的时候,数据只存储在一个 CPU 核心的 Cache 里,而其他 CPU 核心的 Cache 没有该数据。这个时候,如果要向独占的 Cache 写数据,就可以直接自由地写入,而不需要通知其他 CPU 核心,因为只有你这有这个数据,就不存在缓存一致性的问题了,于是就可以随便操作该数据。
- 另外,在「独占」状态下的数据,如果有其他核心从内存读取了相同的数据到各自的 Cache ,那么这个时候,独占状态下的数据就会变成共享状态。
- 那么,「共享」状态代表着相同的数据在多个 CPU 核心的 Cache 里都有,所以当我们要更新 Cache 里面的数据的时候,不能直接修改,而是要先向所有的其他 CPU 核心广播一个请求,要求先把其他核心的 Cache 中对应的 Cache Line 标记为「无效」状态,然后再更新当前 Cache 里面的数据。
-PS: 既然CPU有缓存一致性协议(MESI),为什么JMM还需要volatile关键字?
代码执行
- 程序执行时,会先将内存中的数据加载到共享的 L3 Cache 中,再加载到每个核心独有的 L2 Cache,最后进入到最快的 L1 Cache,之后才会被 CPU 读取。
内存使用
提升数据缓存的命中率
- array[i][j] 执行时间比形式二 array[j][i] 快好几倍
提升指令缓存的命中率
- CPU 的分支预测器。对于 if 条件语句,意味着此时至少可以选择跳转到两段不同的指令执行,也就是 if 还是 else 中的指令。那么,如果分支预测可以预测到接下来要执行 if 里的指令,还是 else 指令的话,就可以「提前」把这些指令放在指令缓存中,这样 CPU 可以直接从 Cache 读取到指令,于是执行速度就会很快。
- CPU 的分支预测器。对于 if 条件语句,意味着此时至少可以选择跳转到两段不同的指令执行,也就是 if 还是 else 中的指令。那么,如果分支预测可以预测到接下来要执行 if 里的指令,还是 else 指令的话,就可以「提前」把这些指令放在指令缓存中,这样 CPU 可以直接从 Cache 读取到指令,于是执行速度就会很快。
- 现代 CPU 都是多核心的,进程可能在不同 CPU 核心来回切换执行,这对 CPU Cache 不是有利的,虽然 L3 Cache 是多核心之间共享的,但是 L1 和 L2 Cache 都是每个核心独有的,如果一个进程在不同核心来回切换,各个核心的缓存命中率就会受到影响,相反如果进程都在同一个核心上执行,那么其数据的 L1 和 L2 Cache 的缓存命中率可以得到有效提高,缓存命中率高就意味着 CPU 可以减少访问 内存的频率。
- 在 Linux 上提供了 sched_setaffinity 方法,来实现将线程绑定到某个 CPU 核心这一功能。
伪共享
- 因为多个线程同时读写同一个 Cache Line 的不同变量时,而导致 CPU Cache 失效的现象称为伪共享(False Sharing)。
- 基于MESI协议的描述,内存中一块数据在多个cache line上时,不同的CPU core不断的交替修改cache line上不同的变量,会导致这些cache line频繁的在invalidate和modified状态之间变化,导致频繁的写入内存。从而失去了cache真正的作用。
避免伪共享
- 在 Linux 内核中存在 __cacheline_aligned_in_smp 宏定义,是用于解决伪共享的问题。
- 避免 Cache 伪共享实际上是用空间换时间的思想,浪费一部分 Cache 空间,从而换来性能的提升。
任务的执行
调度
Linux中进程和线程都是task_struct,单线程时进程就是主线程,多线程时共享了fd和mm_struct(虚拟内存结构体)。
对于内核来说,调度器的对象就是task_struct。
在 Linux 系统中,根据任务的优先级以及响应要求,主要分为两种,其中优先级的数值越小,优先级越高:
- 实时任务,对系统的响应时间要求很高,也就是要尽可能快的执行实时任务,优先级在 0~99 范围内的就算实时任务;
- 普通任务,响应时间没有很高的要求,优先级在 100~139 范围内都是普通任务级别;
Deadline 和 Realtime 这两个调度类,都是应用于实时任务的,这两个调度类的调度策略合起来共有这三种,它们的作用如下:
- SCHED_DEADLINE:是按照 deadline 进行调度的,距离当前时间点最近的 deadline 的任务会被优先调度;
- SCHED_FIFO:对于相同优先级的任务,按先来先服务的原则,但是优先级更高的任务,可以抢占低优先级的任务,也就是优先级高的可以「插队」;
- SCHED_RR:对于相同优先级的任务,轮流着运行,每个任务都有一定的时间片,当用完时间片的任务会被放到队列尾部,以保证相同优先级任务的公平性,但是高优先级的任务依然可以抢占低优先级的任务;
而 Fair 调度类是应用于普通任务,都是由 CFS 调度器管理的,分为两种调度策略:
- SCHED_NORMAL:普通任务使用的调度策略;
- SCHED_BATCH:后台任务的调度策略,不和终端进行交互,因此在不影响其他需要交互的任务,可以适当降低它的优先级。
CPU运行队列
- 每个 CPU 都有自己的运行队列(Run Queue, rq),用于描述在此 CPU 上所运行的所有进程,其队列包含三个运行队列,Deadline 运行队列 dl_rq、实时任务运行队列 rt_rq 和 CFS 运行队列 csf_rq,其中 csf_rq 是用红黑树来描述的,按 vruntime 大小来排序的,最左侧的叶子节点,就是下次会被调度的任务。
- 这几种调度类是有优先级的,优先级如下:Deadline > Realtime > Fair,这意味着 Linux 选择下一个任务执行的时候,会按照此优先级顺序进行选择,也就是说先从 dl_rq 里选择任务,然后从 rt_rq 里选择任务,最后从 csf_rq 里选择任务。因此,实时任务总是会比普通任务优先被执行。