Lambda架构
定义
Lambda架构使用了可以进行大规模数据批处理的MapReduce技术,也使用了可以快速处理数据并及时反馈的流处理技术,这样的混搭能够为大数据问题提供扩展性、响应性和容错性都很优秀的解决方案。
Lambda架构是站在大规模场景的角度来解决问题的,它可以将数据和计算分布到几十台或几百台机器构成的集群上进行。这种技术不但解决了之前因为规模庞大而无法解决的难题,还可以构建出对硬件错误和人为错误进行容错的系统。
Lambda架构源自于它与函数式编程的相似性。从本质上说,Lambda架构是将计算函数施加于大量数据的一种通用方法。
- 不变原始数据是Lambda架构的基础。对于不变的数据进行处理的时候,不在需要锁机制和事物机制。多个线程可以并行地访问数据,而不用担心相互之间的作用。我们可以对数据进行复制,再对副本进行操作,而不用担心数据过期,所以在集群中分布地处理数据就变得非常容易。
传统数据系统的缺陷
扩展性:利用某些技术(比如复制、分片等)可以将传统数据库扩展到多台计算机上,但随着计算机数量和查询数量的增加,应用这种方案会变得越来越困难。超过一定程度,增加计算机资源将无法继续改善性能。
维护成本:维护一个跨多台计算机的数据库的成本是比较高的。如果要求维护时不能停机,那么维护将变得更加困难——比如对数据库进行重新分片。随着数据量和查询数量的增加,容错、备份、确保数据一致性等工作的难度都会呈几何级数增长。
复杂度:复制和分片通常要求应用层面提供一些支持——应用需要知道将查询发给哪一台计算机,以及应该更新哪一个数据分片(每个更新所对应的分片通常不一样,规则也比较复杂)。
- 人为错误
报表和分析:在独立的数据仓库中用另一种格式来维护历史数据。数据从业务数据库向数据仓库的迁移过程就是著名的萃取(extract)、转置(transform)、加载(load)(简称ETL)。这种方案不仅复杂,而且需要准确预测将来我们需要什么信息。有时会碰到这种情况:由于缺乏必要的信息或者信息格式不对,无法生成所需报表或进行某些分析。
批处理视图(批处理层) & 服务层
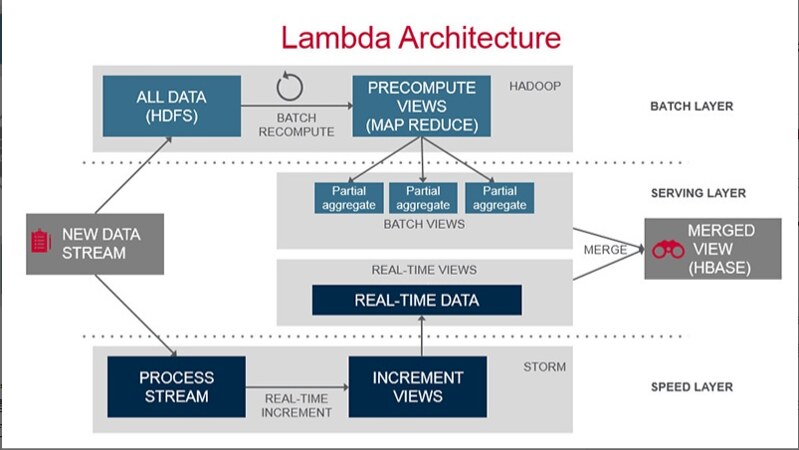
如果能够准确预测出未来会对原始数据进行怎样的查询,就可以预计算出一个批处理视图,这个视图包含这些查询将要返回的衍生信息,或者那些可以计算出这些衍生信息的数据。Lambda架构的批处理层就是用来计算这些批处理视图的。
批处理视图可以包含衍生信息,比如:假设要用一系列编辑记录来构建Wikipedia的页面——批处理视图将只包含从页面的编辑记录中计算得来的页面内容。
批处理视图也可以包含可以计算出衍生信息的数据,这类情况会稍微复杂一些。
需要对生成的批处理视图进行索引,这样就可以对索引进行查询了。另外,还需要一个地方来存放程序逻辑(说明一个查询该如何合并批处理视图的逻辑)。这就是服务层的任务。
- 总结来说利用不变数据利于并行的特显对海量数据进行加工(mapper + reducer),生成批处理视图。然后再通过简单的查询得到想要的结果。
- 后面提到的Hadoop就是应用于批处理层
加速层
有新数据产生时,除了会将数据投入到原始数据还会进行扔给加速层生成实时视图,结合最新的批处理视图可以满足对于新数据的查询。
当新的批处理视图产生后,实时视图就被丢弃了。
这个东西的目的应该是为了快速响应新数据,在批处理层还没有出新版本时,临时使用实时视图+当前最新的批处理视图就组成了未来会出现的批处理视图。
后面讲的Storm系统应用于加速层
最后放一张架构图
MapReduce
定义
MapReduce是一个多义的术语。其可以指代一类算法,这类算法分为两个步骤:对一个数据结构首先进行映射(map)操作,然后进行化简(reduce)操作。之前的词频统计的函数式版本正是这样的例子(frequencies就是用reduce函数实现的)。
MapReduce还可以指代一类系统——这类系统使用了上面的算法,将计算过程高效地分布到一个集群上。这类系统不仅可以将数据和数据处理分布到集群的多台计算机上,还可以在一台或多台计算机崩溃时继续正常运转。
一个MapReduce任务由两种主要的组件构成:mapper和reducer。mapper负责将某种输入格式(通常是文本)映射为许多键值对。reducer负责将这些键值对转换成最终的输出格式(通常也是一系列键值对)。mapper和reducer可以分布在很多不同的计算机上(它们的数目不必相同)。
Hadoop
- 一个包含了MapReduce的
输入通常由一个或多个大文本文件构成。Hadoop对这些文件进行分片(每一片的大小是可配置的,通常为64 MB),并将每个分片发送给一个mapper。mapper将输出一系列键值对,Hadoop再将这些键值对发送给reducer。
一个mapper产生的键值对可以发送给多个reducer。键值对的键决定了哪个reducer会接受这个键值对——Hadoop确保具有相同键的键值对(无论是由哪个mapper产生的)都会发送给同一个reducer处理。这个阶段通常被称为洗牌阶段(shuffle phase)。
Hadoop为每个键调用一次reducer,并传入所有与该键对应的值。reducer将这些值合并,再生成最终输出结果(通常是键值对,也可以不是)。
mapper & reducer
- 书中demo的Map继承了Hadoop的Mapper类,其接受四个类型参数:输入的键类型、输入的值类型、输出的键类型、输出的值类型。它里面的方法本质是将一行文本进行拆分,输出一个键值对。
- 对于每个键,都会调用一次reduce()方法,values是这个键对应的所有值的集合。reduce()方法对这些值进行求和,并产生描述某个单词出现总数的键值对。
- Hadoop在键值对传给reducer前会对键进行排序
Driver
- 从下面的代码看driver就是配置Hadoop。
这里不需要设置输入的键类型和值类型,因为默认情况下Hadoop认为我们处理的是文本文件。也不需要分别设置mapper输出的键/值类型和reducer输入的键/值类型,因为默认情况下Hadoop认为mapper的输出和reducer的输入具有相同的键/值类型。
使用setInputFormatClass()将XmlInputFormat设置为分片器,并且配置xmlinput.start和xmlinput.end来告诉分片器我们关注的是哪个标签。
setCombinerClass()来设置combiner。combiner是一种优化手段,使键值对可以在发往reducer前进行合并。
1 | public class WordCount extends Configured implements Tool { |
Hadoop的优势
- 可以在多台计算机上更快地处理海量的数据
- Hadoop天生就具有处理错误和从错误中恢复的能力,这点很好保证了在使用集群时的稳定性。
- 与上一条相关,不仅要考虑将节点崩溃时正在处理的任务重新执行,还需要考虑当存储发生故障时如何保证数据不丢失。Hadoop默认使用Hadoop分布式文件系统(HDFS),这个有容错能力的分布式文件系统可以在多个节点之间冗余数据。
- 涉及吉字节级别以上的数据时,就不能将所有中间数据或结果全部存放在内存中。Hadoop在处理过程中将键值对存储在HDFS中,这样就可以不受内存限制,完成数据量非常大的任务。
Storm
Spout、Bolt和Topology
Storm系统处理的是元组(tuple)的流。Storm的元组类似于之前我们在第5章看到的actor模型的元组,但不同于Elixir的元组,Storm元组的元素是有名字的。
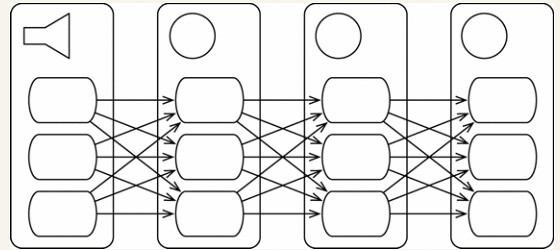
元组由spout(出水管)组件创建,并由bolt(螺栓)组件进行处理,bolt也会输出元组。用流将spout和bolt连接在一起,就形成了topology(拓扑结构)。
topology也可以很复杂——bolt可以消费多个流,而一个流也可以被多个bolt消费,构成一个有向无环图。spout和bolt都是并行化和分布式的。
worker:spout和bolt不仅相互之间是并行的,而且其内部也都是并行的——每一个个体内部都是由很多worker实现的。
下图是一个topology
容错
- 将一个spout或bolt的多个worker分布在多台计算机上的主要原因是容错性。如果集群中的某一台计算机发生故障,topology可以将元组分发给仍存活的计算机,这样topology就可以继续运行。
- Storm会监视元组之间的依赖——如果某一个元组没能完成,Storm会将其依赖的spout元组置为失败并进行重试。这也就是说Storm默认使用的是“至少会执行一次”的处理策略。应用必须知道这个事实:元组可能会被重试,直到其结果正确。
总结
- Lambda目前主要作为大数据平台的架构
- 如果用Hadoop作为Batch Layer,而用Storm作为Speed Layer,那就需要维护两份使用不同技术的代码。所以目前有另外的一个解决方案是Apache Spark,它可以作为Lambda Architecture一体化的解决方案。