AssetBundle
AssetBundle划分过细的问题,比如每个资源都是AssetBundle。
- 加载IO次数过多,从而增大了硬件设备耗能和发热的压力;
- Unity 5.3 ~ 5.5 版本中,Android平台上在不Unload的情况下,每个AssetBundle的加载,其每个文件的SerializedFile内存占用均为512KB(远高于其他平台),所以当内存中贮存了大量AssetBundle时,其SerializedFile的内存占用将会非常巨大。
BuildAssetBundleOptions.DisableWriteTypeTree这个选项的实际用处是什么?
- 在Unity 5.x版本中,AssetBundle在制作时会默认写入TypeTree信息,这样做的好处是可以保证AssetBundle文件的向下兼容性,即高版本可以支持以前低版本制作的AssetBundle文件。
- 所以,如果开启DisableWriteTypeTree选项,则可能造成AssetBundle对Unity版本的兼容问题,虽然关闭TypeTree会使Bundle更小,但我们一般都不建议研发团队在制作AssetBundle文件时开启该选项。
我们项目做AssetBundle打包时,发现如果资源所依赖的C#Script的Public成员变量有变化时,用新代码加载旧的AssetBundle就会不兼容。有没有什么方法能判断这些Script在变化时是否需要重新打AssetBundle呢?目前我们使用.CS文件的MD5来判断是否需要重新打包,但其实这样应该有很多不必要的重复打包,对吗?
- 该问题的本质原因是新代码的序列化信息变化所致。建议研发团队使用Unity 5的新的AssetBundle打包方式,默认情况下,Unity 5引擎会自动检测其脚本的序列化信息是否进行改变,从而自动进行增量打包。
- PS: 虽然已经可以通过升级来解决,但是这个是个需要关注的点。
AssetBundle颗粒度问题
- 详见https://blog.uwa4d.com/archives/TechSharing_59.html 第一个问题
- 总结一下:
- 不要一个资源一个AssetBundle,因为Android上面一个serializedFile有512k,但是5.6后应该是32k。不过实际测试的情况是不一定是32K。WTF。。
- 对于AssetBundle小于1MB的限制在5.4后没意义,之前是因为www走webstream,会导致内存中占用AssetBundle大小4-5倍的空间。但是LZ4后基于其Chunk的加载特点,AB加载很快,且内存占用要比之前小很多。
- 仍旧需要注意的:
- 对于需要热更新的AB,也如问答中其他朋友的所言,要考虑实际情况控制AB的大小;- PS:可能是考虑网络下载的问题,以为过大的文件如果不做断点续传会是恶梦。
- 即便是LZ4的AB,其加载方式不同,加载效率也可能完全不一致。
- 对于AB的打包,尽可能把逻辑上同时出现(一个Prefab中非Share的Asset)、小而细碎的资源(Shader、Material、粒子系统等)尽可能打包在一起,并通过LoadAll来进行加载,因为这样会带来更好的加载效率。
使用LoadFromCacheOrDownload时如果用version参数,缓存的资源如何清除。
- AssetBundle,其Version版本号变化时,新的解压Data是不会覆盖旧的解压Data的。清除旧的解压Data主要有三种方式:
- 设置缓存的过期日期,默认情况下是150天;
- 调用Caching.CleanCache来全部清空缓存;
- 当本地Cache已满时,Unity会从最早的AssetBundle来进行自动清理。
WWW.LoadFromCacheOrDownload(System.String url, Int32 version)这个接口加载资源,如果是Unity 4.x的版本,会有500个资源的数量限制,如果超过这个限制,Unity会删除之前缓存的每个资源,是这样吗?那在Unity 5.x 版本上是否还存在这样的问题呢?
- 在Unity 4.x的版本中,如果通过LoadFromCacheOrDownload来加载AssetBundle,那么有两种情况需要考虑:
-内存中加载的AssetBundle数量。在iOS平台上,通过该接口加载、同时存在于内存中的AssetBundle数量确实是有限的,接近300个,这是由于iOS上文件句柄数的限制导致。而该限制在Unity 5.0以后则被完善了,因为Unity 5引入了虚拟文件系统,所以不再有这个限制;在Android平台上,则没有这个限制,或者说数量限制值非常大,基本可以忽略。- 本地Cache中缓存的AsseBundle数量。无论是iOS、Android还是PC版本,都没有500的数量限制,而是有一个硬盘占用大小限制。具体来说,在WebPlayer平台上,有50MB的缓存限制,而在其他平台上,则是4GB的缓存限制。所以只要硬盘占用大小不超过限定值即可。
Font
我们在内存优化时发现一个问题,编辑器版本 Unity 5.3.4p6,使用UGUI,场景A中一个Text控件使用自定义字体资源,然后把该控件Text属性勾选为空(disable),再Load一个空场景,看场景A卸载后在内存中的残留,发现有一份引用是 ManagedStaticRefrences()的 Font 内存。如果不是把Text属性disable,则场景A卸载后内存里不会再残留被引用的Font内存,请问可能是什么原因造成的呢?
- UWA对于该例子进行了检测,的确能够在 Editor 复现。查了下 UGUI 代码,能对 Font 产生引用的,主要是这个函数 FontUpdateTracker.TrackText(Text),其中会把 t.font 引用起来;而对应的解引用的函数为 FontUpdateTracker.UntrackText。因此,如果出现了两者的调用不匹配,就有可能造成 font 的 ManagedStaticRefrences 引用。
- 进一步查看后,可以看到在定义了 UNITY_EDITOR 宏时,UI 元素会增加一个名为 OnValidate 的函数,Text 组件则在其中进行了 TrackText 的操作。
而最关键的是,该函数在 Text 组件以“未激活”的状态被实例化时同样会被触发,同时,如果这样的 Text 组件在后续没有被激活过就被销毁,其 OnDestroy 和 OnDisable 函数是不会被调用的,参见文档中的这句话:OnDestroy will only be called on game objects that have previously been active.
而 OnDisable 中才会调用 Untrack 解引用,所以造成了不匹配,导致了 font 的 ManagedStaticRefrences。 - 但是,OnValidate 函数只在 Editor 上才有,真机上不会发生上面说到的不匹配的情况。所以建议研发团队先在真机上测试下是否还有这种情况,如果确实没有,那么就忽略该问题即可。
- PS:Mark
Gameplay
我想了解如何使用顶点色Mask控制明暗关系,才能达到类似崩坏琪亚娜效果?
UI
我们游戏中用到NGUI的HUD,单位主要是一个进度条和一个倒计时文本(持续更新),同屏数量达600左右,单位本身在持续移动。现已将这些设置为独立Panel,且只有2个DrawCall(进度条所在图集和文本),但还是卡顿得很厉害,请问是否有优化的方法?
- 简化元素的几何:进度条中的元素尽量避免Sliced 模式(改Simple);倒计时部分如果使用了Outline或者Shadow,将其转为“图片字”;
- 降低更新频率:如倒计时按“秒”统一更新;进度条按1%甚至5%的间隔更新一次;移动速度较慢时可以尝试隔帧更新位置等;
- 拆分子UIPanel:尽可能将更新频率相同的UI元素放在一个UIPanel中,从而降低每次更新时涉及到的UI元素数量。具体的拆分数量,则可能要通过较多的测试来确定。需要说明的是,此处即使增加10到20个DrawCall,对渲染上的影响并不大。
粒子
我们项目中有大量的特效,一个特效Prefab可能包含100-200个GameObject,每个GameObject上都挂有一个粒子系统,但是实际上很多特效只有延时和坐标旋转之类的参数的区别。我看了Prefab文件后发现每个粒子系统分别记录了各自的信息,从而导致整体文件很大,内存占用也比较大。请问是否有优化的方法?
- 如果开发的是一个手游项目,那么一个Prefab下含有100-200个粒子系统是非常不足取的,主要会造成以下几种问题:
- 同时播放100个以上的ParticleSystem,其ParticleSystem.Update本身的CPU占用会很高。下图为一款游戏在华为6Plus上的表现。可以看到Active Particle数量还没有达到100,其Update耗时就已经占到了5ms;
- ParticleSystem.ScheduleGeometryJobs开销会很高。其耗时主要体现在渲染模块中的Culling阶段,与粒子系统的数量相关,场景中Active粒子系统的数量越多,其开销越高;
- 子线程中的渲染压力较大。Unity5.3版本以后,粒子系统的渲染虽然在主线程中占用很小,但并不意味它没有耗时,其耗时在渲染线程中,当渲染线程压力过大时,主线程同样会出现等待(Gfx.WaitForPresent),因此同样可能对帧率产生影响;
- GPU的渲染压力较高。同屏中渲染的粒子系统越多,其屏幕每帧的填充率越高,从而更加容易造成设备的发热;
- 内存压力较高。如果一个Prefab上有100-200个粒子系统,并且如果场景中有10个以上这样的Prefab存在,那么其内存占用将在10~25MB内存区间内。就目前而言,粒子系统仍然是以Clone的形式存在,所以虽然粒子系统可能仅仅是某些参数不同,但其仍然是多个不同的粒子系统。因此,我们在UWA报告中会显示粒子系统在项目运行时的具体显示数量,以方便研发团队对粒子系统进行关注。如下图所示,一般来说,每帧中粒子系统的数量建议在400以下。
模型&动画
网格模型FBX文件在不开启Read/Write选项时, 如果通过StaticBatchingUtility的CombineMesh来合批的话,内存会增加么?
- 增加内存,主要表现在内存中CombinedMesh的增加以及一定量堆内存的增加。
- 该API使用的前提必须是网格Fbx模型开启Read/Write,如果不开启,则无法读到网格数据,进而不能完成网格的拼合操作。
如下图,请问这几个参数的单位是什么?

- Rotation Error使用角度(degree)作为单位。Position和Scale是距离偏差的百分比(曲线调节前后的距离偏差与某距离值之比,取决于Unity内部实现),取值范围1~100,但实际可以高于100,并有作用。
我们建议研发团队在调节该误差时,将调节前后的动画效果进行对比,使文件体积压缩得尽量小,同时使动画效果在视觉上偏差不会太大。 - PS:没找到,可能是动画导入的选项。
如下图,这个ResampleCurves选项的作用,以及是否和对内存性能的影响?
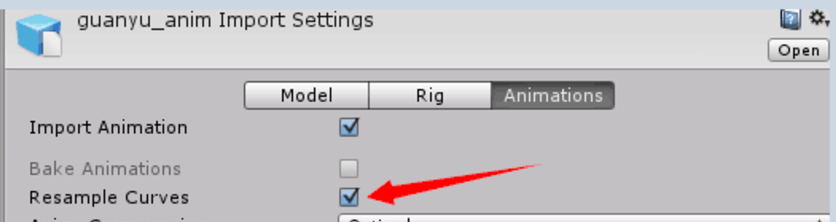
- ResampleCurves选项是在Unity 5.3版本后加入的,在之前的版本中是隐藏并且默认勾选的。该选项会改变Unity动画数据的存储方式。
- 动画文件在导入到Unity之前,其关键帧的数据通常是以欧拉角(Euler format)的方式存储。在勾选该选项时导入,Unity会将欧拉角转换为四元数(Quaternion)表示,并且会生成逐帧的数据(不只是关键帧)。新生成的逐帧数据是为了解决四元数插值问题。关闭该选项会使动画文件保持欧拉角表示,但在应用于GameObject时仍会转换为四元数。
- 建议保持默认勾选该选项,只有当发现Unity中的动画播放效果与在动画编辑工具中的效果出现较大偏差时,尝试取消该选项,查看是否是该选项的原因导致动画偏差。我们在测试中发现该选项对运行性能影响并不明显。在内存方面,勾选该选项会使动画文件略微增加。
动画提出scale
动画模块中,Animators.ProcessAnimationsJob和Animators.WriteJob的CPU占用较高,这些与什么因素有关?
- Animators.WriteJob受模型骨骼数目影响较大(受animation curves影响不明显),骨骼数目越多,该函数耗时越大。同时,开启Optimize GameObject选项能够降低该函数耗时。Animators.ProcessAnimationsJob 同样受骨骼数目影响较大,同时也受animation curves数目影响,二者数目越多,该函数耗时越大。
性能综合
在整体的性能消耗上,CPU和GPU各占一半合理吗?如果不是,各占多少为好?还是说需要根据机型来看?其次,我如何知道游戏在手机上的GPU消耗?Profiler是看不到的,有工具推荐吗?
- 首先,CPU和GPU是并行的,也就是CPU在运算的时候GPU也在运算,一帧的结束时间是两者中比较晚结束的那个。因此,一般我们在考虑这个问题的时候,经常会说是CPU bound还是GPU bound,也就是GPU在等CPU还是CPU在等GPU。
- 最理想的情况是两者都并行均衡,且都没有出现互相等待的情况。但在目前的大多数移动游戏中,都是CPU耗时为主要性能瓶颈。这也是为什么有多线程渲染的原因,多线程渲染就是利用CPU端的并行性,让CPU处理得更快,不拖后腿。
- 对于GPU的压力分析,可以尝试用Intel GPA,Mali或者高通出的针对自家芯片的工具。
为什么Unity里实例化一个Prefab会产生那么多GC Allocated?
- 这是一个特例,但是从里面可以总结出一个问题,就是在Instantiate一个对象时会发生或者可能发生以下的事情
- 序列化和反序列化的处理,因为用prefab生成对象本身就是需要反序列化的。而直接clone一个对象可能还有先序列化在反序列化。
- 可能的资源的加载,比如prefab上用到的mesh、贴图等。
- 可能的shader编译,如果用了一个之前没有用过的shader就会实时的编译。
- 对象身上脚本的初始化。如果实例化一个prefab发现很占用时间要注意是不是脚本里面在awake或者start里面的功能太多了。
- UI界面的Active和Deactive也会造成UI代码底层的一些相关OnEnable和OnDisable操作,同样会造成一定的堆内存分配。
渲染
Unity的材质的宏是有材质用到时才会被编译吗?还是说不手动Skip都会编译?
- 在Unity中shader variant也包含两种类型,一种是通过 shader_feature 定义,一种是通过 multi_compile 定义。而只有通过 shader_feature 定义的 variant 在发布时会根据其使用情况来进行剥离。
- 具体可见Unity官方的文档:https://docs.unity3d.com/Manual/SL-MultipleProgramVariants.html
- 需要注意的是,放在Always Included Shaders中的Shader,其包含的所有 variant 都不会被剥离,因此对于Standard Shader这类包含了大量 shader_feature的Shader,不推荐将其放入。
- PS:没有回答根本的问题:
- Editor中:修改shader并保存时立即编译。
Runtime下,无论哪个平台,都是在进入场景时加载shader object内容到内存,但是首次实际调用渲染时才编译,编译完成之后会cache下来。
有两种优化方法:
调用Shader.WarmupAllShaders(),自动编译该场景中用到的所有shader。该方法在Unity5中已经废弃。
在项目设置的GraphicsSettings中,可以导出ShaderVariantCollection,并在Preloaded Shader中导入,这样的话就可以在载入场景时一并编译需要预加载的shader,这样的优化在移动平台上用得比较多。
具体见
- Editor中:修改shader并保存时立即编译。
听说移动端开启多线程,把后期效果移动到渲染线程会节省后期的消耗。我测试了一下,虽然主线程中后期显示的CPU占用降低了,但是却多了Gfx.WaitForPresent的时间,最后两者相加基本还是一样的。那开启多线程这个功能,对后期到底有没有帮助呢?
- 开启多线程渲染一般情况下会极大降低主线程的渲染耗时,但并不会降低其本身的总体计算量。因为这并不是底层算法或硬件上的提升,而是将部分计算从主线程搬到了子线程。所以,开启多线程的好处在于为主线程带来了大量空间来执行其他耗时模块(如代码逻辑等)。
- 但这并不意味着开启多线程渲染就“万事大吉”。如果渲染模块本身开销就很高,那么子线程一样会很耗时,更有可能出现主线程等待子线程的现象,也就是WaitForPresent开销较高的情况。所以,开启多线程是会降低主线程的渲染压力,但其帧率未必会大幅提升,还需研发团队自行在自己项目中进行尝试和比较。